
L’ho creato per Futuria in 3 mesi. Si chiama SecondBrain. Oggi te lo regalo: puoi ricrearlo adattato alla tua azienda in 30 minuti.
Cinque numeri, per partire dal concreto.
- 27 clienti tracciati come entità vive — attivi, opportunità, partner.
- 137 schede persona — referenti dei clienti, decision-maker, prospect, partner, collaboratori — ognuna con la storia delle interazioni e come gli piace lavorare.
- 175 call archiviate, ognuna con la sua sintesi e i suoi link al cliente, alle persone, alle decisioni che ne sono uscite.
- 62 procedure operative scritte e applicate — dal setup di un nuovo collaboratore al deploy di una modifica sul sito di un cliente.
- 0 ore-persona impiegate ogni mese a tenere aggiornato manualmente tutto questo.
Non sto facendo flex. Sto dicendo una cosa diversa: un anno fa una nostra giornata si apriva aprendo otto strumenti — Google Drive, Gmail, Google Calendar, ClickUp, Futuria CRM, WhatsApp Web, ChatGPT, Slack — e provando a ricostruire a mente cosa era successo ieri con quale cliente. Adesso si apre aprendo un posto. E quel posto sa già tutto, perché si è scritto da solo durante la notte.
Quel posto si chiama SecondBrain. È fatto di file di testo. Lo leggono gli umani come gli agenti AI. Costa zero in licenze. E può vivere sul tuo computer per sempre, anche se domani Anthropic, OpenAI, Google e Obsidian chiudono lo stesso giorno.
Questo articolo racconta cos’è davvero, perché funziona, come l’abbiamo costruito noi, come l’abbiamo dato a Jacopo, Massimo e Farwa, e in fondo trovi un pacchetto da scaricare che contiene tutto quello che serve per partire con il tuo. Non è un tutorial generico di Obsidian. È la condensazione di un mese di setup veri su persone vere, distillata in un bundle che apri con Claude Code o Codex, e gli dici “parti”.
Nota importante, perché qui è facilissimo sbagliare tool: serve Claude Code oppure Codex. Non ChatGPT, non Gemini, non Claude normale nel browser. Il motivo è semplice: il setup deve leggere, creare e modificare file sul tuo computer. Una chat generica può ragionare sul prompt, ma non può costruirti davvero il vault.
Se cerchi i 5 prompt che ti rivoluzioneranno la vita, sei nel posto sbagliato. Se invece da mesi senti la frustrazione di una memoria aziendale che si dissolve ogni volta che chiudi una chat — resta. È il tuo articolo.
Sommario
- Cos’è davvero un SecondBrain (e cosa non è)
- I 4 componenti di un agente — perché il modello è il pezzo meno importante
- La struttura: PARA, e la differenza tra cervello e corpo
- La memoria a tre livelli — la ricetta della zucca
- Quattro cose che cambiano davvero nella tua giornata
- Tre setup veri: Jacopo, Massimo, Farwa
- Le routine che mantengono il vault vivo
- Le cose che non funzionano (e perché ti servono dei guardrail)
- Il pacchetto da scaricare
- Una chiusura sul trapano Makita
1. Cos’è davvero un SecondBrain (e cosa non è)
Partiamo dal disambiguare, perché “SecondBrain” è una di quelle parole che ognuno usa con un significato diverso e poi nessuno si capisce.
Un SecondBrain non è un Google Drive ben organizzato. Non è una cartella con dentro 200 documenti che giuri di rileggere. Non è una raccolta di Google Docs collegati. Non è nemmeno un vault Obsidian con dentro le tue note caotiche del 2022.
Un SecondBrain è il sistema operativo della tua testa, fatto di file di testo organizzati secondo regole rigide, dove vivono in modo strutturato:
- il lavoro che hai fatto
- i progetti in corso
- le decisioni prese (e perché le hai prese)
- le persone che conosci e cosa vi siete detti
- le cose che non hanno funzionato e perché
- le procedure ripetibili
- le credenziali (i metadati, non i valori)
In un formato che sia tu, sia un agente AI potete leggere e usare.
La differenza vera con Google Drive e simili non è cosmetica: è che qui la conoscenza è navigabile dall’AI come se fosse una Wikipedia personale. Ogni file ha link diretti agli altri, e l’agente li esplora come faresti tu cliccando da una pagina Wikipedia all’altra. Quando gli chiedi “dimmi cosa abbiamo deciso a marzo con quel cliente del settore edile”, lui non cerca nel cloud sperando di trovare la frase giusta. Apre la cartella di quel cliente, legge l’overview, vede il link al file delle decisioni, lo apre, ti dice cosa avete deciso e cita la riga.
Il file rimane leggibile a te. Tu vedi esattamente cosa l’agente sta leggendo. Se sbaglia, sai dove correggere. Se cambi modello AI domani — passi da Claude a un altro — il vault funziona uguale, perché è solo testo. La conoscenza è tua, non del fornitore.
Questa cosa qui — la navigabilità + la portabilità + il fatto che è tutto leggibile in chiaro — è la differenza tra un secondo cervello vero e un’altra app che dimenticherai tra sei mesi.
C’è poi una cosa più sottile, che capisci solo quando ci sei dentro da qualche settimana: il vault smette di essere un posto dove metti le cose. Diventa un posto da cui le cose escono già pronte.
Mi spiego. Tu durante la giornata produci roba: una nota di call che butti giù di getto, una decisione presa al volo, un dubbio che hai messo da parte, una mail importante che non vuoi perdere. Tutta questa roba va in un’unica cartella che si chiama 00_Inbox/. Non la classifichi tu. Non la sposti tu. Durante la notte, una procedura automatica — l’agente — la legge, capisce di cosa parla, e la sposta dove serve. Le note di una call con un cliente finiscono nella cartella di quel cliente. I dubbi sull’advertising finiscono nell’area advertising. Le decisioni strategiche entrano nel file delle decisioni corretto. La mattina dopo apri il vault e l’inbox è vuota. Il sapere di ieri è già al posto suo, già linkato, già richiamabile.
Questa è la promessa. Adesso vediamo come funziona davvero.
2. I 4 componenti di un agente — perché il modello è il pezzo meno importante
Quando la gente pensa “AI” pensa al modello. ChatGPT. Claude. Gemini. È il pezzo che tutti vedono. È anche il pezzo meno importante.
Un agente AI utile è fatto di quattro cose, in quest’ordine di importanza reale:
- Contesto — a quali dati ha accesso in tempo reale. Cosa sta vedendo mentre risponde.
- Memoria — come archivia e ritrova le informazioni nel tempo. Cosa ricorda di te tra una sessione e l’altra.
- Strumenti — cosa può fare. Non solo leggere, ma agire: aprire file, chiamare un’API, mandare una mail.
- Intelligenza — il modello sotto. Claude, GPT, qualunque…
Sembra un dettaglio tecnico, è la cosa più importante di tutto l’articolo. Lo ripeto.
Un agente con un buon contesto e una buona memoria, anche se gira su un modello mediocre, batte sempre un agente con il modello migliore del mondo ma senza memoria e senza accesso a niente. Sempre. Senza eccezioni.
Tradotto in italiano da imprenditore: non serve la versione più costosa del modello AI. Serve un vault ben fatto.
Questa cosa la capisco bene perché vediamo arrivare clienti che hanno fatto esattamente l’errore opposto. Uno è arrivato dopo aver speso quattordicimila euro su una piattaforma “AI all-in-one” in cui nessuno del suo team aveva mai messo mano davvero.
Né la titolare, né i due commerciali, né la marketer. Era una scatola che girava in automatico mentre il lavoro vero continuava a vivere su WhatsApp e in mail. Il modello AI sotto era ottimo. Il contesto a cui aveva accesso era zero. La memoria che si stava costruendo era zero. Risultato: una bolletta mensile che pagava un fornitore per produrre un servizio che non era mai partito.
L’AI, da sola, non fa l’azienda funzionare. È il sostrato che la fa funzionare se sopra ci hai costruito le altre tre cose.
Quando in questo articolo dico “agente”, quindi, non intendo una chat AI generica. Intendo un ambiente operativo come Claude Code o Codex, aperto su una cartella locale, con il permesso di leggere il bundle, creare file, sistemare cartelle, verificare cosa esiste già e fermarsi quando rischierebbe di sovrascrivere qualcosa. ChatGPT, Gemini o Claude nel browser possono aiutarti a capire l’idea. Non sono lo strumento giusto per eseguire questo setup.
Una conseguenza pratica di questo: la conoscenza non deve vivere nella testa dell’AI. Deve vivere nel sistema. Si chiama principio dell’intercambiabilità, e risolve un problema con cui chiunque usi l’AI nel lavoro convive ogni mese.
Il problema è questo. Ogni settimana esce un modello nuovo. Anthropic rilascia una versione più potente di Claude, e nel mentre OpenAI annuncia GPT-5. Google esce con un Gemini più veloce. Il giorno dopo qualcuno ti dice che in realtà per il coding Codex va meglio, mentre per scrivere conviene Claude, e per fare ricerca strutturata serve un altro modello ancora.
Tu ci provi, ti adatti, ti abitui — e dopo due mesi ne è uscito un altro che dovresti provare. Nel mentre, ogni volta che cambi tool ti porti dietro un dubbio fastidioso: “Questo qui ormai sa così tante cose di me, ho passato mesi a istruirlo. Se cambio, ricomincio da zero?”
Con il SecondBrain questo problema sparisce. La conoscenza non vive nella memoria del tool. Vive in locale, nei file markdown del tuo vault. Tu domani passi da Claude a Codex perché esce una versione di Codex che fa una cosa nuova che ti serve — apri Codex sul tuo vault, e Codex ha accesso allo stesso identico sapere che aveva Claude. Niente onboarding ripetuto. Niente “ricomincio da capo”. L’agente cambia, la knowledge resta tua. È nei tuoi file, sul tuo computer.
E il giorno in cui — sicuro, prima o poi succede — esce un modello ancora migliore di entrambi, lo apri sul vault e parte da dove eravate arrivati. Il modello è il pezzo che si aggiorna ogni tre mesi. Il vault è quello che resta per anni.
Questo è il primo pilastro mentale. Tienilo: contesto e memoria contano più del modello. Il resto dell’articolo ti spiega come si costruiscono.
3. La struttura: PARA, e la differenza tra cervello e corpo
Adesso la struttura del vault. Sembra noioso. È invece il punto su cui tutto il resto si regge o crolla.
Il vault ha sei cartelle alla radice. Sei. Non sette, non cinque. Sei. Si chiama PARA con un’aggiunta nostra:
00_Inbox/— il limbo. Tutto ciò che arriva e non è ancora stato classificato.10_Progetti-interni/— progetti con una fine. Cose che a un certo punto chiudi.20_Areas/— aree di responsabilità continuative. L’agenzia, il prodotto, le finanze personali, la salute. Niente deadline, vivono per sempre.30_Resources/— sapere riusabile. Procedure, persone non-cliente, credenziali, knowledge cross-cliente, template.40_Progetti-esterni/— qui vive il grosso del lavoro: una cartella per ogni cliente attivo o in trattativa.90_Archive/— l’archivio. Quando un progetto chiude, viene qua. Mai cancellato, solo spostato.
Sei posti. Sei funzioni. Quando ti arriva qualcosa di nuovo, prima di metterla da qualche parte ti chiedi: in quale di queste sei va? Se la risposta è “non lo so” — non crei una settima cartella. Riformuli la domanda. Quasi sempre la risposta esiste, e se non esiste vuol dire che la cosa va in 00_Inbox/ finché non hai capito.
Le eccezioni una alla volta sembrano innocue. Una cartella nuova qui, una sotto-cartella là, un file fuori posto perché “tanto è solo uno”. Sono il modo in cui i vault muoiono. Tre mesi dopo non trovi più niente, e quello che era organizzato è tornato a essere caos vestito da ordine.
C’è poi una distinzione fondamentale che voglio nominare e poi non approfondisco, perché sennò esce un articolo nell’articolo: il SecondBrain è solo il cervello. Esiste anche un corpo, separato. Il vault contiene file leggibili — markdown, testo, decisioni, knowledge. Tutto il resto — video sorgente, file Photoshop, repository di codice, dataset enormi, render — vive in un’altra cartella, parallela al vault, che chiamiamo Workspace.
Detto questo, torniamo al cervello.
Ogni cartella del vault ha un file che si chiama _overview.md. Quel file è la mappa locale: dichiara cosa vive lì dentro, cosa non vive lì dentro, e linka i contenuti principali. Senza _overview.md, la cartella per l’agente non esiste. Letteralmente: lui parte sempre dall’overview, e se non c’è non entra. Questa cosa qui è quella che permette al vault di restare navigabile anche quando hai mille file. L’agente non si perde, perché non vaga: salta da overview in overview, e dentro ogni overview ha la mappa di dove sta andando.
Vista da lontano, questa struttura non assomiglia più a una cartella ordinata. Assomiglia a un grafo: clienti, aree, call, persone, decisioni e procedure che si richiamano tra loro.
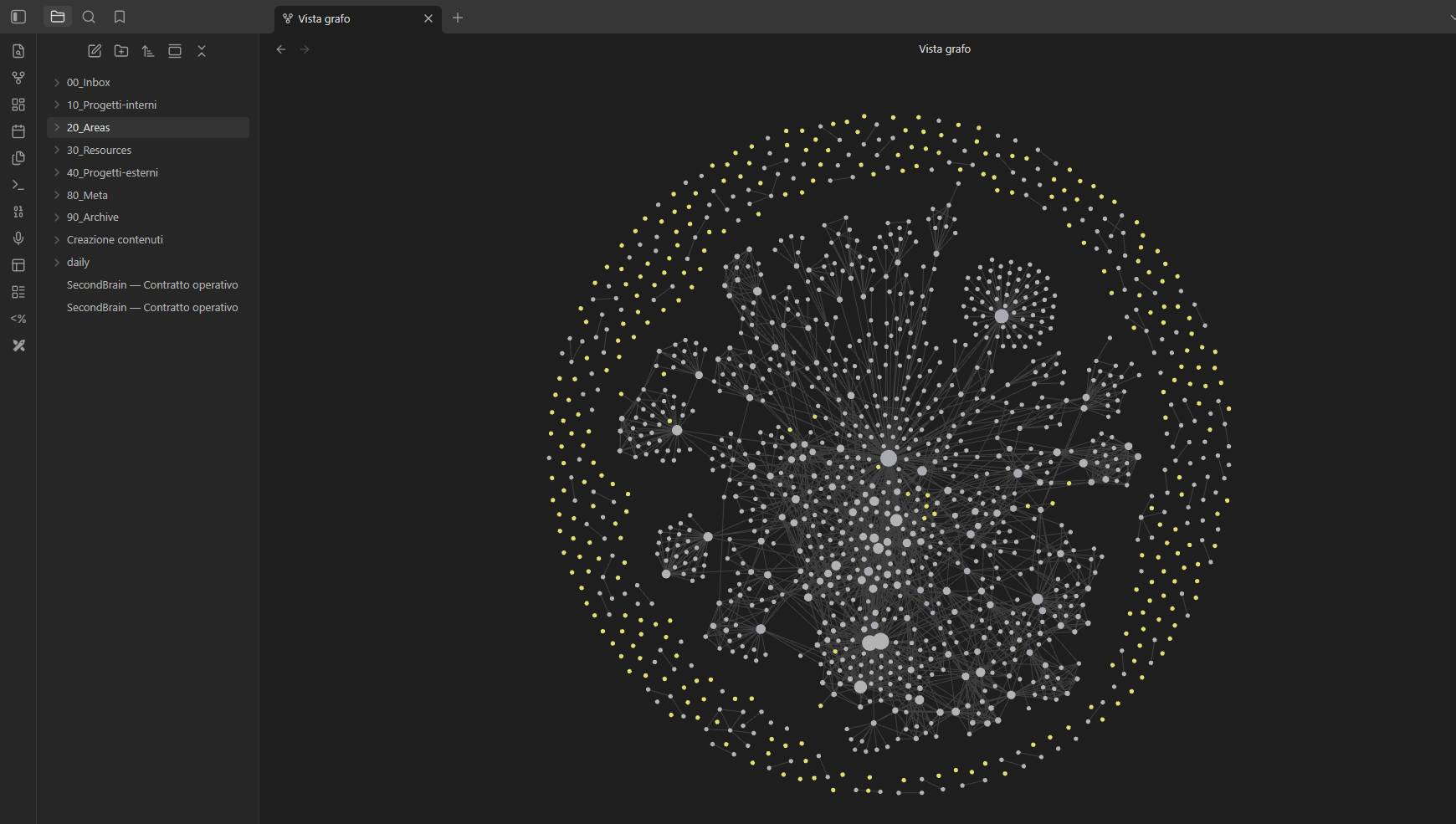
La vista ravvicinata rende meglio il punto: il valore non è “avere tanti file”. È avere file che sanno dove puntare. Quando l’agente entra nel vault, non sta cercando alla cieca in un mucchio di documenti: segue relazioni esplicite.

L’altra cosa importante è il file CLAUDE.md alla radice del vault. È il contratto operativo globale. Dice all’agente: tu sei nel mio vault, mi chiamo Fabrizio, lavoro così, queste sono le mie regole, queste sono le mie aree, questo è dove vanno le cose. È il primo file che l’agente legge ogni volta che apri una sessione. Senza, sta andando alla cieca.
Questa è l’ossatura. Sei root, un overview per ogni cartella, un contratto globale alla radice. È l‘80% di cosa serve per cominciare.
4. La memoria a tre livelli — la ricetta della zucca
Vengo a una metafora che uso da quando ho cominciato a spiegare questa cosa, e che mi ha confermato di funzionare quando l’ho usata con Jacopo a maggio durante la sua call di setup.
Pensa a un cuoco. Un bravo cuoco, che lavora da vent’anni in cucina.
Quel cuoco ha una competenza generale. Sa cucinare. Sa che il sale prima dell’acqua, il burro a freddo, la pasta scolata un minuto prima. Queste cose non le va a leggere ogni volta. Sono dentro di lui.
Poi ha delle ricette in testa. Quelle che fa più spesso, quelle che gli vengono naturali. Non tutte le proporzioni esatte, ma il senso, la struttura, i passaggi principali. Le richiama velocemente quando serve.
E poi ha un libro di ricette della zucca, in cucina, sullo scaffale. Lì dentro ci sono cose specifiche: quanti grammi per quattro persone, a che temperatura, per quanto tempo. Quelle non se le ricorda a memoria. Sa che esistono, sa dove andarle a prendere, e le va a leggere solo quando deve fare quella cosa precisa.
La memoria di un agente AI nel tuo vault funziona esattamente così, su tre livelli:
Livello 1 — Sempre attivo. È il CLAUDE.md alla radice. Regole globali, identità, struttura del vault, tono. L’agente lo legge all’inizio di ogni sessione. È il “sapere cucinare” del cuoco. Cose che non si discutono, sono lì sempre.
Livello 2 — Richiamabile velocemente. Sono gli _overview.md di ogni area, più i file memory.md e decisions.md dei singoli clienti o aree. L’agente li legge quando entra in una zona del vault. “Sto entrando in un progetto di un cliente? Apro l’overview di quel cliente, guardo la sua memory, vedo se ci sono decisioni rilevanti.” È la ricetta in testa: la richiama quando serve, ma non la tiene caricata sempre.
Livello 3 — On-demand. Sono i file specifici. Trascrizione di una call di tre mesi fa. Documento tecnico su un’integrazione particolare. Versione 7 del codice di una gift option che non funzionava per via di Iubenda. Questi l’agente li va a prendere solo se servono per quella specifica risposta. È il libro delle ricette della zucca: si apre quando devi cucinare la zucca, e basta.
Questa struttura a tre livelli risolve il problema più stupido e più ricorrente di tutti gli agenti AI: il fatto che dimenticano. Una conversazione ricomincia da zero ogni volta perché la “memoria” della maggior parte degli agenti è solo la finestra di contesto della sessione corrente. Apri una nuova chat, addio.
Con i tre livelli, no. L’agente parte sempre con il CLAUDE.md caricato — sa chi sei, come lavori, cosa fa la tua azienda. Quando gli dici “lavoriamo su Farway”, lui apre l’overview di Farway, che ha già le decisioni storiche, le persone, il tono di voce, lo stack tecnico. Gli stai dando in tre file quello che a un nuovo dipendente daresti in tre giorni di onboarding. E se gli serve un dettaglio — la versione esatta del checkout, la specifica di un campo CSV, la trascrizione di una call con la fondatrice — lui sa esattamente in quale file andarlo a leggere.
Non sa tutto. Sa dove andare a vedere tutto. È la differenza che fa.
5. Quattro cose che cambiano davvero nella tua giornata
A questo punto puoi aver capito la teoria e ancora chiederti: “ok, ma in pratica cosa cambia per me, lunedì mattina?”
Tu lo sai già che l’AI ti può aiutare a risolvere tanti problemi. Lo usi probabilmente da mesi. Però lo sai anche che ogni volta devi rispiegare tutto quanto da capo: chi sei, cosa fai, di che cliente stiamo parlando, qual era il contesto. E sai che, anche dopo averglielo spiegato per la terza volta nella stessa settimana, non ti capisce mai veramente fino in fondo, perché alla prossima sessione si è dimenticato di nuovo.
Con il SecondBrain questa cosa qui non la devi più fare. L’agente ha già il contesto. Lo ha sempre. La differenza pratica è che cose che oggi sono un mezzo giorno di lavoro diventano un quarto d’ora. Non perché l’AI sostituisce te. Perché smette di farti combinare a mente informazioni che oggi vivono in cinque posti diversi. E quasi sempre — questa è la parte che la gente sottovaluta — anche le cose che sembrano più banali, in realtà richiedono di pescare da tre o quattro fonti diverse.
Te ne mostro quattro vere, di tipi di cosa che facciamo noi adesso e che prima erano sempre più dolorose di così.
Caso 1 — Stai per entrare in una call con un cliente che non senti da settimane
Tra cinque minuti hai una call. È un cliente che non senti da sei settimane. Hai dato un’occhiata al calendario, hai visto il nome, e ti rendi conto che non ricordi bene di cosa avevate parlato l’ultima volta. Perché in mezzo ci sono passati altri venti clienti, tre call di vendita, un incidente tecnico, due fiere e un weekend che volevi staccare.
Apri il vault, scrivi all’agente: “Sto per entrare in call con [cliente]. Briefami in 30 secondi.”
L’agente, in 30 secondi reali, fa quattro cose insieme:
- Apre la sua scheda persona — chi è, ruolo, decision-maker o referente, come gli piace essere trattato, parole da non usare, quirk personali (uno di loro è permaloso sui prezzi, un altro vuole sempre i numeri prima del concept).
- Legge l’overview del cliente che lui rappresenta — settore, dimensione, da quanto lavorate insieme, su cosa state lavorando adesso.
- Si guarda le ultime tre call con lui — di cosa avete parlato, decisioni prese, cose in sospeso.
- Controlla il
decisions.mdper vedere se c’è una decisione recente che lui potrebbe star tirando in ballo.
In 30 secondi ti consegna un brief: “Probabilmente vuole parlarti di X. L’ultima decisione su questo è del 18 aprile, era Y. Attenzione a non rinominare il prodotto come ‘sistema’ — lui lo chiama sempre ‘piattaforma’ e ci tiene. Ha una scadenza fiscale a fine mese, è probabilmente sotto stress.”
Entri in call e hai già la testa nella conversazione giusta. Niente “scusa un attimo che cerco la mail”. Niente fare finta di ricordare. Niente prendere appunti in fretta su cose che ti aveva già detto.
Provo a fare il conto di quante volte al giorno ti capita una versione di questa scena. Per chi gestisce 20-30 clienti attivi, è la metà degli appuntamenti. Senza vault, quei 30 secondi sono tre minuti di ricerca + un quarto d’ora di conversazione meno produttiva. Con vault, sono 30 secondi e una conversazione che parte già al punto giusto.
Caso 2 — Posizionare il tuo prodotto su Google senza essere un esperto SEO
Capire come posizionarsi sui motori di ricerca, fino a un anno fa, era una cosa per cui chiamavi un consulente SEO senior, gli pagavi 3-4.000 euro, ti consegnava un PDF dopo tre settimane, e poi tu non sapevi bene cosa farci.
Adesso, con il vault, è una giornata. Ti faccio l’esempio di Farway Milano, un brand DTC di abbigliamento bambino premium di Milano, fondato da Farwa Zulfiqar.
Il 28 aprile abbiamo prodotto per loro una keyword research aggiornata in mezz’ora. Mezz’ora vera, non un modo di dire. Non perché abbiamo trovato un tool magico. Perché il vault aveva già dentro, da settimane, le cose che a un consulente SEO esterno avresti dovuto raccontare:
- Il design system del brand (palette colori, font, posizionamento “smart luxury anti-fast-fashion”).
- Il tono di voce consolidato (direct response, anti-luxury, storytelling autentico) ricavato da settimane di lavoro su email marketing.
- I prodotti reali del catalogo — 72 articoli con varianti già caricati nel sito.
- Il contesto storico del brand — rilanciato a marzo 2026 dopo aver perso 50.000 euro per il fallimento di un retailer di Brera.
- Le email della welcome series che stiamo testando — quindi quali angoli stanno già funzionando con il pubblico.
- Le decisioni strategiche prese nelle call con la fondatrice negli ultimi due mesi.
L’agente ha letto tutto questo, lo ha incrociato con dati di mercato esterni (volumi di ricerca, intent, competitor), e ha tirato fuori una keyword research che parlava davvero di Farway. Non un PDF generico “sì-le-keyword-da-targettizzare-sono-vestiti-bambino”. Una mappatura per fasi del funnel, con le keyword giuste per ogni angolo già validato dal copy della welcome series, con le esclusioni di cosa non andare a inseguire (parole chiave troppo generiche o troppo lusso classico, che non sono il loro pubblico).
Un SEO senior la stessa cosa l’avrebbe fatta in 4 giorni, perché avrebbe dovuto prima fare due call per capire il brand, poi consultare il design system, poi guardarsi i prodotti, poi farsi spiegare il tono. Tutte cose che il vault aveva già dentro.
Il punto operativo è uno solo: una cosa che sembra banale (la keyword research) richiede in realtà di combinare brand, prodotti, posizionamento, mercato, tono di voce, esperimenti già fatti, dati esterni. Senza un posto unico dove tutta questa roba viva, quella combinazione la fai a mano ogni volta. Con il vault, l’agente la fa in mezz’ora.
E nel mentre Farwa, che è la fondatrice e CEO, può continuare a fare il suo lavoro — vendere abbigliamento bambino — invece di passare due giornate a essere intervistata da un consulente esterno.
Caso 3 — Modificare qualcosa sul sito di un cliente che hai costruito tre mesi fa
Questo è il caso che a noi capita due o tre volte a settimana, e che senza vault è un piccolo incubo.
Il cliente ti scrive: “Ciao, ho bisogno di cambiare quella cosa sul checkout. Te lo ricordi?”. (No, non te lo ricordi.)
Sul checkout di tre mesi fa avevi messo nove versioni di codice diverse. Non perché eri scemo, ma perché c’era un sistema cookie compliance — Iubenda — che intercettava ogni singolo script che metteva mano ai cookie, e per nove volte lo aveva bloccato. Alla decima versione avevi trovato il modo di farglielo digerire: scrivere lo script come file esterno servito dallo stesso dominio, offuscare i pattern “cookie” nel sorgente, inserire il DOM come fratello (e non figlio) del subtree React di WooCommerce per evitare che il re-render lo cancellasse ogni volta che il cliente cambiava metodo di pagamento.
Tre mesi dopo non ricordi nessuna di queste cose. Senza vault, le riscopri facendo gli errori da capo. Sono tre giorni buttati.
Con vault, succede questo.
Apri Claude Code o Codex, scrivi: “Devo modificare la gift option al checkout di Farway, ricordami cosa avevamo fatto e perché.”
L’agente apre 40_Progetti-esterni/farway/lessons.md, trova le voci sul gift option, ti riassume in 60 secondi: l’iniezione DOM, il workaround Iubenda, il pattern ufficiale extensionCartUpdate adottato per la V10, il fatto che lo scope dello snippet deve essere global e non front-end. Cita il codice canonico — file snippet20_gift-option.php, ID 39 sul DB di produzione, attualmente active=0.
Poi ti dice anche dove sono le credenziali per il database (30_Resources/Credentials/farway--mysql-db.md), come si fa il deploy via SSH+MySQL (c’è uno script Python già pronto), e ti ricorda che il path SSH sul server è diverso dal path SFTP — confondere i due ti era già costato un’ora la volta scorsa.
E ancora — perché qui sotto succede una cosa che non si vede ma è importante — l’agente non ha “saputo” tutto questo. È andato a leggerselo. Ha pescato da lessons.md, da decisions.md, dal file delle credenziali, dal worklog. Quattro fonti diverse, combinate in una risposta sola.
Tu ti siedi e fai la modifica in due ore invece che in tre giorni. La differenza non è “l’AI ha scritto il codice al posto mio” (non l’ha fatto). È: l’AI ti ha dato in tre minuti il contesto che ti sarebbe costato un mezzo giorno di lavoro a recuperare a mente.
Caso 4 — Preparare una demo (o un’icebreaker, o una call commerciale) che parte dal punto giusto
Ultimo caso, e forse il più ad alto valore di tutti, perché tocca direttamente il commerciale.
Quando in Futuria si prepara una demo del nostro CRM con un’azienda che non conosciamo ancora, prima dell’AI le cose stavano così: il commerciale apriva LinkedIn, leggeva quattro cose, apriva il sito, apriva Atoka per i dati di bilancio, apriva la mail in cui il prospect aveva scritto qualcosa di sé, prendeva appunti su un foglio, e arrivava in call cinque minuti prima sperando di ricordarsi tutto.
Quaranta minuti di prep per call, fatti da mani diverse, con risultato che variava enormemente. E in call, sistematicamente, quei primi 40 minuti se ne andavano nel rifare le domande di base — “raccontami chi siete, da quanto, in quanti, cosa fate” — perché non si poteva entrare nello specifico senza prima ricostruire il quadro.
Adesso funziona così. Prima della call, l’agente costruisce una scheda azienda del prospect. Pesca da:
- Atoka/Cerved per dati anagrafici, dimensione, fatturato (se disponibile).
- Sito web del prospect per posizionamento e linguaggio.
- LinkedIn del decision-maker per ruolo, storia professionale, contenuti pubblicati.
- Eventuali mail scambiate prima della call.
- Call precedenti del nostro team con quella persona o con qualcuno della stessa azienda (se ce ne sono).
L’agente mette tutto in formato standard. Dichiara le fonti. E — questa è la parte che mi piace di più — quando un dato non lo trova lo dice nero su bianco. Non se lo inventa.
Esempio reale: Market Color, microimpresa storica di Rubiera (RE), esiste dal 1987, 4 dipendenti. Quando abbiamo preparato la prima call con Alessandro Iaccheri, il fondatore, l’agente ha trovato dipendenti, anzianità, dimensione. Il fatturato non l’ha trovato — non c’erano fonti pubbliche affidabili. E ha scritto, nella scheda: “Il fatturato resta non confermato; finché non emerge una fonte più robusta o una visura ufficiale, non va usato alcun numero di ricavi in documenti operativi o strategici.”
Questa è la differenza tra un’AI utile e un’AI dannosa. Quella dannosa avrebbe inventato un numero plausibile. La nostra ha scritto “non lo so, non scrivetelo da nessuna parte”. È stata istruita ad essere così. Si chiama guardrail e ne parlo dopo.
Risultato in call: invece di chiedere ad Alessandro 35 minuti di “raccontatemi chi siete”, lui ci ha trovati già preparati. Si è sentito preso sul serio. Noi abbiamo recuperato 30 minuti di tempo. La conversazione è partita dal posto giusto — quello strategico — invece che dalla fase 0.
Anche qui, sotto il cofano: la scheda è un combinato di sei o sette fonti. Una persona da sola può farla in 40 minuti se è brava. L’agente la fa in 5, e in modo più costante perché non dimentica nessuna fonte.
Quattro casi, un solo tema sotto: le cose che sembrano banali nel lavoro quotidiano richiedono in realtà di combinare informazioni che vivono in posti diversi. Il valore del SecondBrain non è “fa una cosa”. È “tiene insieme le cose, e quando ne combini quattro o cinque insieme ti restituisce ore di vita”.
Adesso passiamo alla parte in cui ti racconto come l’abbiamo fatto fare ad altre persone.
6. Tre setup veri: Jacopo, Massimo, Farwa
Il SecondBrain l’abbiamo costruito prima per Futuria, perché ne avevamo bisogno noi. Poi, una volta che funzionava, lo abbiamo cominciato a dare ad altri. In un mese, tre persone diverse, tre situazioni diverse. Ogni setup ci ha insegnato qualcosa che è diventato parte del bundle che oggi distribuisco.
Te le racconto in ordine cronologico, perché si vede bene come è evoluto il sistema.
Jacopo — il founder che ha generato il template canonico
Jacopo Viola è un founder che gestisce più progetti in parallelo. Quello su cui sta puntando di più è Videogo, una startup nel mondo video che vuole diventare il suo core business. Nel mentre porta avanti altri ambiti operativi che lo tengono attivo mentre Videogo cresce. Più progetti, più contesti, più AI session che ricominciavano da zero ogni volta. Una vita di knowledge che viveva nelle chat e si dissolveva con loro.
Il 5 maggio abbiamo fatto una call di un’ora insieme. Risultato: non un vault costruito al volo, ma una mappa di come sarebbe stato il vault di Jacopo se l’avesse costruito lui. Dopo la call gli ho mandato un deliverable scritto — un singolo file markdown di una decina di pagine — che descriveva la sua struttura specifica, le sue aree, le sue regole di routing, il suo CLAUDE.md adattato. Lui apre Claude Code, carica il file, scrive “Iniziamo l’onboarding del vault”, e l’agente prende da lì.
Quella call e quel deliverable hanno generato una cosa che non mi aspettavo: il template canonico del bundle. Per fare il setup di Jacopo ho dovuto formalizzare cose che fino a quel momento erano ovvie a me ma non documentate da nessuna parte — la differenza vault/Workspace, il significato esatto degli _overview.md, la gerarchia delle regole, le tre routine di mantenimento. Da allora quei materiali vivono nel vault Futuria come SOP riusabile, e sono diventati il pacchetto che oggi distribuisco a chiunque.
La lesson più importante da Jacopo è una sola, ed è banalissima: per insegnare una cosa devi prima codificarla. Per costruire il bundle abbiamo dovuto fare il setup vero a una persona vera. Non sarebbe uscito dalla mia testa in astratto, neanche se ci avessi provato per un mese.
Massimo — il broker che mi ha insegnato a frantumare il setup
Massimo Ciprandi è un broker assicurativo. Founder di Aegis Intermedia. 1.300 clienti gestiti, 26 compagnie mandatarie con cui lavora. Allo stesso tempo sta costruendo un’altra cosa: Business Roundtable, una rete di imprenditori che sta franchisando per replicarla in altre città italiane. Eventi mensili da circa 80 partecipanti. Capitoli da aprire in più sedi. Un’evoluzione del classico modello BNI con un costo molto più basso per l’iscritto.
Quando gli ho proposto di costruire il suo SecondBrain, mi ha detto subito una cosa che ho registrato come una correzione importante: “Fabrizio, io non ho mai un’ora di seguito di concentrazione. Mai. Non posso dirti quando.”
Il setup standard che avevo usato con Jacopo era una sessione lineare di un’ora-due, da inizio a fine. Per Massimo non funzionava.
Allora abbiamo fatto un esperimento: frantumarlo in due macrofasi, separate tra loro da quanto serve.
- Macrofase A — 15 minuti reali. L’agente assume default sensati (4 aree pre-impostate sul suo profilo: Aegis, Business Roundtable, Gruppo, Personale), li conferma in blocco e fa lo scaffolding. A fine macrofase A, Massimo ha un vault scaffoldato, plugin Obsidian installati, una
_overview.mddi esempio popolata. Può chiudere e tornare al lavoro. - Macrofase B — quando ha 30-60 minuti di concentrazione vera. L’agente lo intervista una area alla volta, con tre domande mirate per ogni area, popola memory/decisions/worklog dove emergono dati reali, e configura le routine notturne sul suo stack effettivo (Zoho Mail, WhatsApp Business, il sistema ZO che usa per il protocollo di Business Roundtable).
Risultato: Massimo è entrato nel sistema senza dover bloccare due ore di calendario che non esistono. Il vault è cresciuto a tappe, calibrato su come lavora lui davvero.
La lesson che ho imparato da Massimo è uscita di lì ed è diventata canonica: il bundle si adatta alla persona, non viceversa. Adesso, quando consegno il pacchetto a un nuovo destinatario, faccio una valutazione preliminare — chi sei, come lavori, quanto tempo continuativo hai davvero — e calibro l’override del flusso. Per i founder pieni come Massimo, la variante 2-macrofasi. Per chi ha un’ora consecutiva, il setup lineare. Per i casi più complessi, una versione ulteriormente segmentata.
Farwa — la cliente che è anche utente del sistema
Farwa Zulfiqar è la fondatrice di Farway Milano, il brand di abbigliamento bambino di cui ti ho parlato sopra. È il caso più interessante dei tre perché racconta cosa succede quando il SecondBrain entra dentro la relazione tra agenzia e cliente — non solo dentro la testa del singolo che lo costruisce.
Tutto il lavoro che facciamo con Farwa — il sito WooCommerce con i suoi snippet PHP custom, il rilancio del brand a marzo dopo aver perso 50.000 euro per il fallimento di un retailer, la welcome series di sei email su Futuria CRM, il design system, il tono di voce direct response anti-luxury — vive in un posto solo, organizzato in modo che chiunque del team Futuria possa entrarci e ritrovare il filo in cinque minuti. Questo è quello che permette poi alla keyword research di uscire in mezz’ora, alla call di partire dal punto giusto, alla modifica tecnica al checkout di non costare tre giorni di “rimettersi in pari”.
Il punto interessante è qui: il SecondBrain non serve solo a chi lo costruisce per sé. Serve anche a chi sta dentro alle organizzazioni che lo usano per servirlo meglio. Il cliente finale ne riceve i frutti senza nemmeno sapere che esiste, perché vede solo il fatto che l’agenzia risponde più in fretta, ricorda tutto, prepara il lavoro al primo colpo invece che dopo tre giri di mail.
Ed è anche il motivo per cui questo bundle, quando lo distribuisci dentro un’agenzia o un team commerciale, ha un impatto a cascata molto più grande di quello del singolo. Una persona che adotta il SecondBrain serve meglio i suoi 20 clienti. Cinque persone in un team che lo adottano insieme — costruendo un vault condiviso — moltiplicano l’effetto.
Tre persone, tre forme diverse della stessa cosa. Da Jacopo è uscito il template. Da Massimo l’idea che il template va spezzato sui vincoli di tempo reali. Da Farwa la conferma che il vault non serve solo a te, serve a chi lavora con te.
7. Le routine che mantengono il vault vivo
Ho promesso che non avrei fatto il pippone tecnico. Mantengo. In quattro paragrafi vi dico cosa girano ogni notte sopra il vault Futuria, e perché senza queste tre cose il sistema decade in pochi mesi.
Una. C’è una routine che si chiama nightly-ingest che parte ogni notte alle 22:01. Si va a guardare le call registrate e trascritte dalla giornata, le mail rilevanti, le note buttate nell’inbox, e mette tutto al posto suo. Una nota relativa a un cliente finisce nella sua cartella. Una decisione strategica finisce nel file decisioni corretto. Tu la mattina apri il vault e l’inbox è vuota.
Due. C’è una routine che si chiama hygiene che gira tre volte a settimana (lunedì, mercoledì, venerdì alle 9:01). Si va a comprimere le voci di worklog ridondanti, identifica candidati all’archivio, segnala anomalie strutturali. Un manutentore che fa quello che fareste voi nel weekend se ne aveste voglia (spoiler, non ne avete).
Tre. C’è una routine che si chiama weekly-profile-update che gira il lunedì mattina presto. Aggiorna le schede persona dei collaboratori sulla base delle call della settimana. Se nei tuoi 1-to-1 con un membro del team è emersa una preferenza di lavoro nuova, una difficoltà, un’evoluzione di ruolo, lunedì mattina la sua scheda persona ce l’ha aggiornata.
Tutte queste routine condividono una proprietà che fuori dal mondo tecnico nessuno usa mai e che andrebbe usata sempre: sono idempotenti. Significa che le puoi rilanciare dieci volte di fila e il risultato è uguale a se le avessi lanciate una. Niente duplicati, niente note in doppio, niente “aspetta, l’ho già fatto?”. Una proprietà che separa un’automazione che ti aiuta da un’automazione che devi sorvegliare.
Una nota importante: queste routine non si installano subito. Quando fai il setup del tuo SecondBrain dal pacchetto, le hai a disposizione come SOP scritte ma non attive. Le accendi quando il vault ha contenuto reale — diciamo dalla terza/quarta settimana — perché farle girare su un vault vuoto non serve a niente.
8. Le cose che non funzionano (e perché ti servono dei guardrail)
Ho promesso un articolo onesto. Allora dico anche le cose che vanno gestite bene, altrimenti il sistema si ritorce contro. Tre lessons dolorose da non saltare.
Uno: AI senza guardrail è una bomba a tempo. A noi è successo, una volta, di generare un asset visivo per un post — non un cliente, era contenuto interno. L’AI ha messo in pagina un logo che non esisteva, su un’azienda reale. L’abbiamo visto in tempo, non è uscito. Da quel giorno c’è una policy nel vault, asset-generation-policy, che vieta esplicitamente all’agente di inventare loghi, nomi brand, dati, numeri di fatturato, claim di campagna. Quando serve un asset visivo con il logo del cliente, l’agente prepara il layout con uno spazio bianco riservato. Il logo lo metto io a mano (o lo recupera lui dalla cartella brand reale del cliente, se la trova). Sembra banale. Senza, in sei mesi avremmo prodotto un asset al mese con un’inesattezza. Prima o poi, sarebbe finita pubblicata.
Due: nessuna comunicazione esce dall’agente senza approvazione umana. Una mail vuota inviata a un cliente — anche questo, episodio reale, nostro, non da AI ma da un workflow buggato. Il principio si applica uguale. L’agente prepara la bozza. L’umano clicca invia. Sempre. Il fatto che tecnicamente l’AI possa inviare email da sola non significa che debba farlo. Su questo siamo tassativi.
Tre: l’AI nel customer service che esiste solo perché altri ce l’hanno è teatro. Ho visto aziende mettere agenti AI in chat con i clienti perché si vergognavano a non averli. Senza un processo dietro, senza una memoria, senza guardrail. L’esito è sempre lo stesso: clienti incazzati di parlare con un bot stupido, dipendenti che devono comunque intervenire, e zero risparmio reale. Il test vero per qualunque pezzo di AI che vuoi mettere in azienda è uno: senza, cosa cambierebbe operativamente? Se la risposta è “niente di importante”, l’AI non serve. È solo costo.
E a monte di tutto: l’AI non è un sostituto di un processo. Se il processo che hai in azienda è storto, l’automazione lo accelera e basta. Lo schianto arriva prima, ma più forte.
9. Il pacchetto da scaricare
Eccoci alla parte che hai aspettato.
Tutto quello che ho descritto fin qui — la struttura PARA, i tre livelli di memoria, l’agente di onboarding, le routine notturne, i guardrail, la calibrazione personale — è impacchettato in una serie di file markdown che devi usare dentro Claude Code oppure Codex.
Lo dico in modo volutamente netto: non incollarlo in ChatGPT, Gemini, Claude.ai o in un’altra chat AI normale. Non perché siano “scarsi”, ma perché qui non serve solo una risposta. Serve un agente che lavori su file locali: deve scaricare il bundle, leggere istruzioni, creare cartelle, scrivere markdown, controllare se Obsidian e Python esistono, e fermarsi se trova un conflitto.
Il pacchetto contiene, in sintesi:
- Il framework concettuale completo — i 4 componenti dell’agente, la gerarchia degli accessi, la memoria a tre livelli, i principi canonici. Quello che ti serve sapere prima di partire.
- L’architettura del vault — la struttura PARA, la separazione cervello/corpo, le regole di routing. Quello che ti serve sapere mentre costruisci.
- Lo starter del CLAUDE.md — il template del contratto operativo da popolare nella root del tuo vault. Quello che l’agente leggerà ogni volta che apri una sessione.
- L’agente di onboarding — la persona del SecondBrain Assistant, con il protocollo a fasi che ti guida dal primo
mkdiral primo_overview.mdpopolato. Il file che apre la sessione: lo carichi, scriviparti(o “iniziamo l’onboarding del vault”), e prende da lì. - Le routine di mantenimento —
nightly-ingest,hygiene,weekly-profile-update, e il pre-flightvault-lint. Le SOP astratte, da installare quando il vault avrà contenuto vero. - Un leggimi che spiega come usare il bundle e cosa aspettarsi.
Mappa di orientamento, prima di partire:
- Apri una cartella locale vuota o dedicata al tuo nuovo SecondBrain.
- Apri Claude Code o Codex dentro quella cartella.
- Incolli il prompt qui sotto.
- L’agente scarica il bundle da GitHub e legge i file nell’ordine corretto.
- Verifica ambiente, Obsidian, Python ed eventuali vault già esistenti.
- Ti fa una mini-intervista per capire chi sei, cosa gestisci e quanto tempo hai.
- Crea o adatta la struttura del vault: cartelle,
_overview.md,CLAUDE.md, routine evault-lint.py. - Chiude la Macrofase A con una verifica e ti propone la Macrofase B, dove si popola il sistema con clienti, aree, persone e decisioni reali.
Cosa ti serve avere prima:
- Claude Code oppure Codex installato sul tuo computer (uno dei due, basta).
- 30 minuti di concentrazione vera, una volta. Tanto basta per arrivare al vault scaffoldato, l’agente attivo, le aree definite, il
CLAUDE.mdpopolato — un sistema che da quel momento è già operativo e già tuo. Il popolamento delle aree con i tuoi clienti, le tue decisioni, le tue persone è la parte che fai a tappe nei giorni successivi, dieci minuti per volta, quando hai una pausa tra due call. Non serve bloccare mezza giornata.
L’installazione di Obsidian, lo scaffolding delle cartelle, l’attivazione dei plugin, la configurazione del CLAUDE.md — tutto questo è parte del setup guidato. Non devi avere niente preparato in anticipo, e nemmeno scaricare nulla a mano. Il bundle vive in un repository pubblico su GitHub, e l’agente se lo clona da solo all’avvio della prima sessione.
L’esperienza che vivrai è questa: apri Claude Code o Codex in una sessione pulita, scegli il modello più avanzato disponibile e imposta il massimo livello di ragionamento, poi incolli un singolo prompt — quello che trovi qui sotto — e premi invio. L’agente clona il bundle, legge i file nell’ordine giusto, assume il ruolo di “SecondBrain Assistant di Futuria”, e parte dalla Macrofase A dell’onboarding. Ti chiede una manciata di cose mirate (chi sei, su che computer sei, cosa gestisci nella vita lavorativa), propone una struttura calibrata, e — dopo che hai confermato — comincia a costruire. A fine sessione hai un vault scaffoldato sul tuo disco, con le aree definite, un primo _overview.md di esempio popolato, e tutta la struttura per farci entrare il sapere reale nei giorni successivi. Se hai un’agenda pienissima come Massimo e non hai 30 minuti consecutivi, l’agente sa anche frantumare il setup in due tappe ancora più corte — è una variante che abbiamo canonizzato proprio per i casi come il suo.
Prima di copiarlo, ultimo promemoria operativo: questo prompt va incollato solo in Claude Code o Codex, aperti nella cartella in cui vuoi lavorare. Se lo incolli in ChatGPT, Gemini o Claude normale, al massimo ottieni una spiegazione elegante del setup. Il vault, però, resta da costruire. Meraviglioso per la retorica, pessimo per il lunedì mattina.
Ecco il prompt da copiare e incollare. Nient’altro:
Clona o aggiorna il repository https://github.com/FuturiaMarketing/secondbrain-bundle dentro una sottocartella `bundle/` della cartella corrente.
Se `bundle/` non esiste, clonalo lì.
Se `bundle/` esiste già ed è lo stesso repository Git, aggiornalo alla versione più recente.
Se `bundle/` esiste ma non è quel repository, non cancellare nulla: fermati e chiedimi come procedere.
Dopo il download, leggi nell'ordine questi file:
1. `bundle/README.md`
2. `bundle/BOOTSTRAP.md`
3. `bundle/.claude/skills/secondbrain-assistant/SKILL.md`
4. `bundle/01-framework-e-principi.md`
5. `bundle/02-architettura-vault-e-workspace.md`
6. `bundle/03-claude-md-starter.md`
7. `bundle/04-agente-secondbrain-assistant.md`
8. `bundle/05-stack-discovery.md`
9. tutti i file Markdown dentro `bundle/routines/`
10. `bundle/meta/scripts/vault-lint.py`
Poi assumi il ruolo di "SecondBrain Assistant di Futuria" come descritto nel bundle.
Il tuo obiettivo è guidarmi fino ad avere un Second Brain personale installato, configurato e manutenibile.
Devi partire dalla Macrofase A dell'onboarding, seguendo il processo previsto dal bundle:
- auto-rilevamento ambiente;
- verifica se Obsidian è installato;
- verifica se esiste già un vault;
- verifica se Python è disponibile;
- mini-intervista iniziale;
- scelta del percorso più adatto;
- setup tecnico;
- creazione o adattamento della struttura del vault;
- copia delle routine;
- copia dello script `vault-lint.py`;
- creazione della struttura `80_Meta`;
- verifica finale.
Durante il setup usa i livelli operativi AUTO / PROPOSE / ASK del template `CLAUDE.md` come contratto operativo.
Fai domande direttamente in chat quando ti servono informazioni dall'utente. Non usare strumenti o funzioni proprietarie non portabili per fare domande.
Quando completi la Macrofase A, non aspettare che sia io a chiedere il passo successivo: proponi autonomamente la Macrofase B, spiegando cosa farà e chiedendo conferma prima di procedere.
Tre dettagli pratici, perché vale la pena saperli prima di partire:
- Apri Claude Code o Codex in una sessione pulita (nuova, vuota, senza altro contesto già caricato). È importante: l’agente deve partire da zero per assumere correttamente il ruolo di SecondBrain Assistant.
- Scegli il modello più avanzato disponibile e abilita il livello di ragionamento massimo. Il setup non è lavoro banale — comporta decisioni strutturali che condizionano i prossimi anni del tuo vault, e vuoi un modello che ragioni bene su ognuna.
- Quando il prompt parte, lui clona il bundle da solo dentro la cartella corrente. Non serve fare git clone a mano. Non serve scaricare zip. Non serve niente prima.
Una nota importante: il pacchetto è vivo. Lo aggiorniamo quando emerge una variante nuova (è successo con Massimo, succederà ancora). Se rilanci il prompt tra due mesi, l’agente prende automaticamente la versione aggiornata dal repository — non resti indietro con una copia vecchia.
Un’altra nota, più sottile: se durante il setup emerge un caso che il bundle non copre — succede — l’agente è istruito a non risolverlo come eccezione locale nel tuo vault. La cosa giusta da fare in quel caso è segnalarcelo: ci scrivi, lo guardiamo, valutiamo se diventa estensione del bundle per tutti. La rigidità globale è quello che permette al sistema di essere replicabile.
10. Una chiusura sul trapano Makita
C’è una metafora che uso da mesi, e che funziona: comprare un trapano Makita di gamma alta e usarlo per piantare chiodi. Funziona, certo. Ma stai usando uno strumento progettato per fare cose impossibili a mano per fare le cose stupide che facevi prima a mano.
L’AI senza un SecondBrain sotto è esattamente questo: un Makita usato per piantare chiodi. Fai più velocemente le stesse cose mediocri che facevi prima.
L’AI con un SecondBrain sotto fa cose che a mano non avresti mai nemmeno tentato — leggere centinaia di call e tirarne fuori un posizionamento, preparare una scheda azienda incrociando sei fonti in cinque minuti, ricordarti di una decisione tecnica di tre mesi fa quando il cliente ti chiama all’improvviso.
Tutto quello che ti ho raccontato — i quattro casi quotidiani, le tre storie di setup, il bundle scaricabile — converge su un’unica cosa: smettere di tenere a mente quello che potrebbe vivere nel sistema. Non per delegare. Per liberare la mente per quello che effettivamente solo tu puoi fare: decidere, vedere connessioni, parlare con le persone, capire dove sta andando l’azienda nei prossimi 24 mesi.
Tutta la roba operativa — chi mi ha detto cosa, quando, perché, dove avevo messo quel file, qual è il pattern che funziona con quel tipo di cliente — è materiale che il vault tiene per te molto meglio di quanto la tua testa possa tenerlo. La tua testa ha cose più importanti da fare.
Se hai una PMI che senti rumorosa — quei contatti che entrano e si perdono, quelle decisioni che finiscono dentro WhatsApp e non si trovano più, quegli strumenti che hai pagato e nessuno usa, quelle conversazioni con i clienti in cui ti senti sempre in ritardo di un beat — ti capisco. Ci siamo passati. Adesso abbiamo un modo di guardarlo che funziona.
Scarica il pacchetto. Apri Claude Code o Codex. Scrivi parti. Dacci qualche ora del tuo tempo, una volta. Dopo, il sistema diventa tuo per sempre.
E se durante il setup ti perdi, o se emerge una cosa che il bundle non copre, scrivimi. Davvero. Quel feedback è quello che fa crescere il pacchetto per chi viene dopo di te.
Buon lavoro.
— Fabrizio Romano, Futuria Marketing
P.S. — Ho scritto questo articolo perché volevo che fosse utile, non perché volesse essere virale. Se sei arrivato fin qui, vuol dire che ha funzionato almeno un po’. Adesso però mi serve il tuo feedback vero. Non quello di cortesia, quello onesto.
Cosa è chiaro? Cosa è confuso? Quale sezione hai saltato e quale hai riletto due volte? C’è un caso che ti sembra troppo bello per essere vero? Una cosa che vorresti vedere approfondita nel prossimo articolo? Una parte del setup che ti spaventa o ti sembra fuori portata?
Scrivimi. Davvero. Rispondi a questa mail, lascia un commento, mandami un messaggio su LinkedIn — il canale lo scegli tu. Quello che mi torna indietro lo uso per scrivere meglio i prossimi pezzi e per migliorare il bundle. Non per profilarti, non per metterti in una sequenza, non per niente che non sia capire come essere più utile.
Grazie.


